AI models are now capable of independently identifying high-severity vulnerabilities in complex software. As Anthropic recently documented, Claude discovered more than 500 zero-day vulnerabilities - security flaws unknown to software maintainers - in well-tested open-source software.
This post describes a collaboration with researchers at Mozilla in which Claude Opus 4.6 uncovered 22 vulnerabilities over the course of two weeks. Of those, Mozilla classified 14 as high-severity - nearly a fifth of all vulnerabilities reported that period.
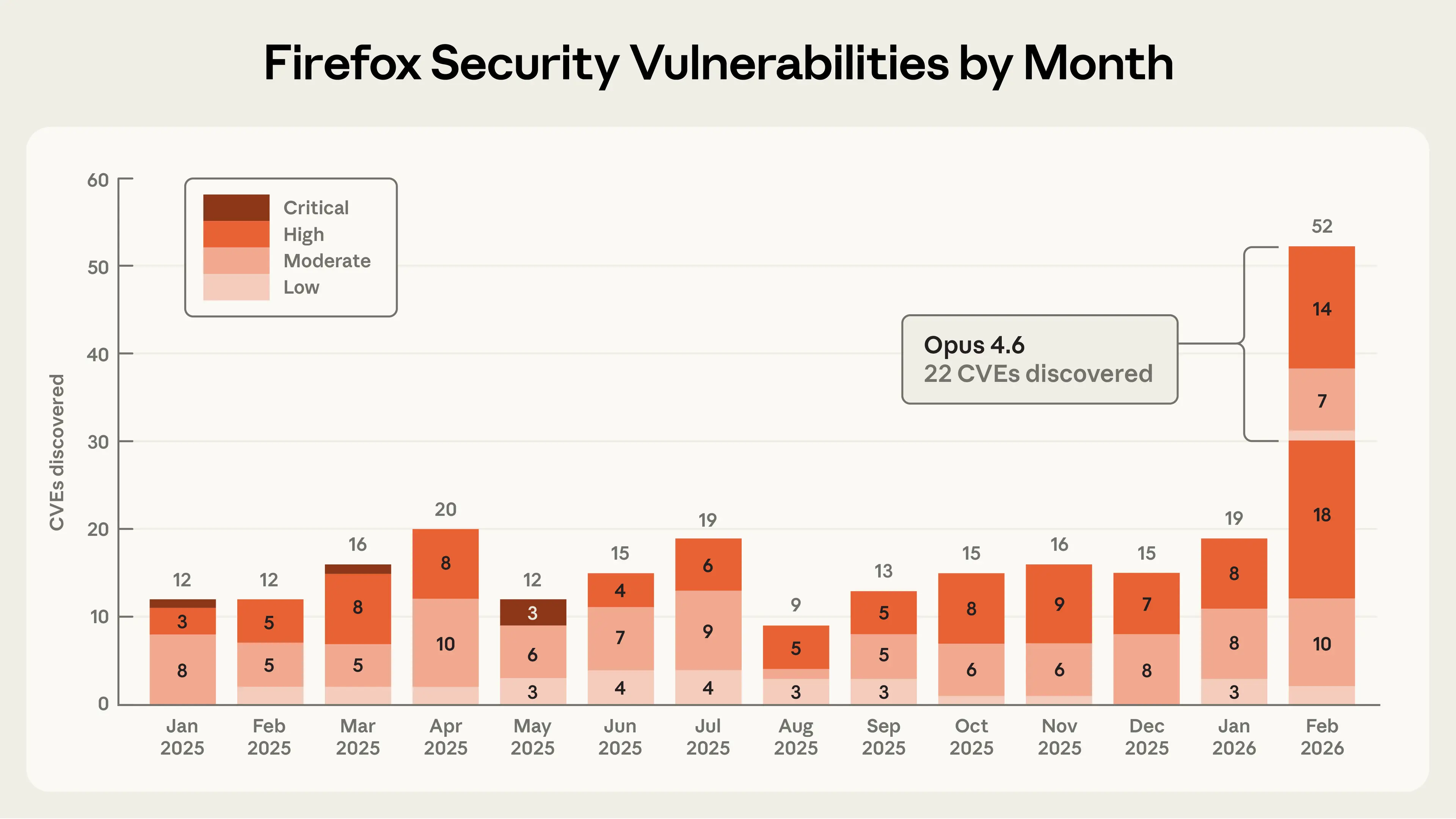 Firefox security vulnerabilities reported from all sources, by month. Claude Opus 4.6 identified 22 vulnerabilities in February 2026, surpassing the total reported in any single month during 2025.
Firefox security vulnerabilities reported from all sources, by month. Claude Opus 4.6 identified 22 vulnerabilities in February 2026, surpassing the total reported in any single month during 2025.
As part of this effort, Mozilla handled a large volume of reports from Anthropic, helped the team understand which findings warranted formal bug reports, and shipped fixes to hundreds of millions of users in Firefox 148.0. Mozilla's partnership and the technical lessons learned offer a model for how AI-enabled security researchers and maintainers can collaborate effectively.
From model evaluations to a security partnership
In late 2025, Anthropic noticed that Opus 4.5 was close to solving all tasks in CyberGym, a benchmark that tests whether LLMs can reproduce known security vulnerabilities. The team wanted to build a harder, more realistic evaluation containing a higher concentration of technically complex vulnerabilities, like those found in modern web browsers. So they constructed a dataset of prior Firefox common vulnerabilities and exposures (CVEs) to see if Claude could reproduce them.
Firefox was chosen because it is both a complex codebase and one of the most well-tested and secure open-source projects in existence - making it a tougher test of AI's ability to find novel security flaws than previously used open-source software. Hundreds of millions of users depend on it daily, and browser vulnerabilities are especially dangerous because users routinely encounter untrusted content and rely on the browser for protection.
The first step involved using Claude to find previously identified CVEs in older versions of the Firefox codebase. Anthropic was surprised that Opus 4.6 could reproduce a high percentage of these historical CVEs, given that each originally took significant human effort to uncover. However, it remained unclear how much to trust this result, since at least some of those historical CVEs might have been present in Claude's training data.
So Anthropic tasked Claude with finding novel vulnerabilities in the current version of Firefox - bugs that by definition could not have been reported before. The initial focus was on Firefox's JavaScript engine, later expanding to other parts of the browser. The JavaScript engine was a convenient starting point: it is an independent slice of the codebase that can be analyzed in isolation, and it is especially important to secure given its wide attack surface (it processes untrusted external code when users browse the web).
After just twenty minutes of exploration, Claude Opus 4.6 reported that it had identified a Use After Free - a type of memory vulnerability that could allow attackers to overwrite data with arbitrary malicious content - in the JavaScript engine. One of Anthropic's researchers validated the bug in an independent virtual machine running the latest Firefox release, then forwarded it to two other Anthropic researchers, who also confirmed it. The team then filed a bug report in Bugzilla, Mozilla's issue tracker, along with a description of the vulnerability and a proposed patch (written by Claude and validated by the reporting team) to help triage the root cause.
In the time it took to validate and submit this first vulnerability, Claude had already discovered fifty more unique crashing inputs. While Anthropic's team was triaging these crashes, a Mozilla researcher reached out. After a technical discussion about respective processes and sharing a few more manually validated vulnerabilities, Mozilla encouraged Anthropic to submit all findings in bulk without validating each one individually, even if the team was not confident that every crashing test case had security implications. By the end of the effort, nearly 6,000 C++ files had been scanned and a total of 112 unique reports were submitted, including the high- and moderate-severity vulnerabilities mentioned above. Most issues have been fixed in Firefox 148, with the remainder slated for upcoming releases.
When performing this kind of bug hunting in external software, Anthropic is always aware that something critical about the codebase may have been missed, potentially making a discovery a false positive. The team tries to do due diligence by validating bugs internally, but there is always room for error. Anthropic is extremely appreciative of Mozilla for being so transparent about their triage process and for helping adjust Anthropic's approach to ensure only relevant test cases were submitted. Mozilla researchers have since begun experimenting with Claude for internal security purposes.
From identifying vulnerabilities to writing primitive exploits
To measure the upper limits of Claude's cybersecurity abilities, Anthropic also developed a new evaluation to determine whether Claude could exploit any of the discovered bugs - in other words, whether Claude could develop the kinds of tools a hacker would use to take advantage of these vulnerabilities to execute malicious code.
To do this, Claude was given access to the vulnerabilities submitted to Mozilla and asked to create an exploit targeting each one. To prove successful exploitation, Claude was required to demonstrate a real attack: specifically, reading and writing a local file on a target system, as an attacker would.
This test was run several hundred times with different starting points, costing approximately $4,000 in API credits. Despite this, Opus 4.6 was only able to turn a vulnerability into a working exploit in two cases. This reveals two things: first, Claude is much better at finding bugs than exploiting them; second, the cost of identifying vulnerabilities is an order of magnitude cheaper than creating an exploit for them. However, the fact that Claude could succeed at automatically developing a crude browser exploit, even if only in a few cases, is concerning.
"Crude" is an important caveat. The exploits Claude wrote only worked in Anthropic's testing environment, which intentionally removed some security features found in modern browsers - most importantly, the sandbox, which is designed to reduce the impact of these types of vulnerabilities. Firefox's "defense in depth" would have been effective at mitigating these particular exploits. But sandbox-escape vulnerabilities are not unheard of, and Claude's attack represents one necessary component of an end-to-end exploit. More details about how Claude developed one of these Firefox exploits are available on Anthropic's Frontier Red Team blog.
What's next for AI-enabled cybersecurity
These early signs of AI-enabled exploit development underscore the importance of accelerating the find-and-fix process for defenders. With that goal in mind, Anthropic has shared several technical and procedural best practices developed during this analysis.
First, when researching "patching agents" - which use LLMs to develop and validate bug fixes - Anthropic has developed methods that should help maintainers use LLMs like Claude to triage and address security reports faster.[^1]
In Anthropic's experience, Claude works best when it can check its own work with another tool. This class of tool is referred to as a "task verifier": a trusted method for confirming whether an AI agent's output actually achieves its goal. Task verifiers give the agent real-time feedback as it explores a codebase, allowing it to iterate deeply until it succeeds.
Task verifiers helped discover the Firefox vulnerabilities described above,[^2] and in separate research, Anthropic found they are also useful for fixing bugs. A good patching agent needs to verify at least two things: that the vulnerability has actually been removed, and that the program's intended functionality has been preserved. In this work, tools were built that automatically tested whether the original bug could still be triggered after a proposed fix, and separately ran test suites to catch regressions (changes that accidentally break something else). Maintainers will likely know best how to build these verifiers for their own codebases; the key point is that giving the agent a reliable way to check both properties dramatically improves output quality.
There is no guarantee that all agent-generated patches passing these tests are ready to merge immediately. But task verifiers increase confidence that a produced patch will fix the specific vulnerability while preserving program functionality - achieving what is considered the minimum requirement for a plausible patch. When reviewing AI-authored patches, maintainers should apply the same scrutiny they would to any other patch from an external author.
Zooming out to the process of submitting bugs and patches: Anthropic recognizes that maintainers are overwhelmed. Therefore, Anthropic's approach is to give maintainers the information they need to trust and verify reports. The Firefox team highlighted three components of Anthropic's submissions that were key for trusting the results:
- Accompanying minimal test cases
- Detailed proofs-of-concept
- Candidate patches
Anthropic strongly encourages researchers who use LLM-powered vulnerability research tools to include similar evidence of verification and reproducibility when submitting reports based on the output of such tooling.
Anthropic has also published its Coordinated Vulnerability Disclosure operating principles, describing the procedures used when working with maintainers. These processes follow standard industry norms for now, but as models improve, adjustments may be needed to keep pace with capabilities.
The urgency of the moment
Frontier language models are now world-class vulnerability researchers. On top of the 22 CVEs identified in Firefox, Anthropic has used Claude Opus 4.6 to discover vulnerabilities in other important software projects like the Linux kernel. Over the coming weeks and months, Anthropic will continue to report on how its models are being used and how the company is working with the open-source community to improve security.
Opus 4.6 is currently far better at identifying and fixing vulnerabilities than at exploiting them, which gives defenders the advantage. And with the recent release of Claude Code Security in limited research preview, Anthropic is bringing vulnerability-discovery and patching capabilities directly to customers and open-source maintainers.
However, looking at the rate of progress, it is unlikely that the gap between frontier models' vulnerability discovery and exploitation abilities will last very long. If and when future language models break through this exploitation barrier, additional safeguards or other actions will be needed to prevent misuse by malicious actors.
Anthropic urges developers to take advantage of this window to redouble their efforts to make their software more secure. For its part, Anthropic plans to significantly expand its cybersecurity efforts, including working with developers to search for vulnerabilities (following the CVD process outlined above), developing tools to help maintainers triage bug reports, and directly proposing patches.
If you're interested in supporting Anthropic's security efforts - writing new scaffolds to identify vulnerabilities in open-source software; triaging, patching, and reporting vulnerabilities; and developing a robust CVD process for the AI era - apply to work at Anthropic here.
[^1]: All the advice shared here is based on Anthropic's use of Claude, but it should apply to whichever LLM you prefer. [^2]: Which Mozilla patched independently.